During a recession, home prices suffer. How do college towns compare to other communities? Let's find out. But first, a few definitions.
-
A quarter is a specific three month period, Q1 is January through March, Q2 is April through June, Q3 is July through September, Q4 is October through December.
-
A recession is defined as starting with two consecutive quarters of GDP decline and ending with two consecutive quarters of GDP growth.
-
A recession bottom is the quarter within a recession, that had the lowest GDP.
-
A university town is a city that has a high percentage of college students compared to the total population of the city.
Hypothesis
College towns have their mean housing prices less affected by recessions. Run a t-test to compare the ratio of the mean price of houses in university towns the quarter before the recession starts compared to the recession bottom. Values less than one show home price increases, and values greater than one, show home price declines.
Data
-
From the Zillow research data site there is housing data for the United States. In particular, the data file for all homes at a city level,
zillow_homes_prices_by_city.csv, has median home sale prices at a fine-grained level. -
From the Wikipedia page on college towns is a list of college towns in the United States and saved as
college_towns.txt. -
From Bureau of Economic Analysis, US Department of Commerce, the GDP over time of the United States in current dollars (use the chained value in 2009 dollars), in quarterly intervals, in the file
gdplev.xls. For this project, I only look at GDP data from the first quarter of 2000 onward.
import pandas as pd
import numpy as np
import seaborn as sns
from scipy.stats import ttest_ind
# Use fully spelled out place names
states = {'OH': 'Ohio', 'KY': 'Kentucky', 'AS': 'American Samoa', 'NV': 'Nevada', 'WY': 'Wyoming', 'NA': 'National', 'AL': 'Alabama', 'MD': 'Maryland', 'AK': 'Alaska', 'UT': 'Utah', 'OR': 'Oregon', 'MT': 'Montana', 'IL': 'Illinois', 'TN': 'Tennessee', 'DC': 'District of Columbia', 'VT': 'Vermont', 'ID': 'Idaho', 'AR': 'Arkansas', 'ME': 'Maine', 'WA': 'Washington', 'HI': 'Hawaii', 'WI': 'Wisconsin', 'MI': 'Michigan', 'IN': 'Indiana', 'NJ': 'New Jersey', 'AZ': 'Arizona', 'GU': 'Guam', 'MS': 'Mississippi', 'PR': 'Puerto Rico', 'NC': 'North Carolina', 'TX': 'Texas', 'SD': 'South Dakota', 'MP': 'Northern Mariana Islands', 'IA': 'Iowa', 'MO': 'Missouri', 'CT': 'Connecticut', 'WV': 'West Virginia', 'SC': 'South Carolina', 'LA': 'Louisiana', 'KS': 'Kansas', 'NY': 'New York', 'NE': 'Nebraska', 'OK': 'Oklahoma', 'FL': 'Florida', 'CA': 'California', 'CO': 'Colorado', 'PA': 'Pennsylvania', 'DE': 'Delaware', 'NM': 'New Mexico', 'RI': 'Rhode Island', 'MN': 'Minnesota', 'VI': 'Virgin Islands', 'NH': 'New Hampshire', 'MA': 'Massachusetts', 'GA': 'Georgia', 'ND': 'North Dakota', 'VA': 'Virginia'}
def get_list_of_university_towns():
"""Returns a DataFrame of towns and the states they are in from the
university_towns.txt list. The format of the DataFrame should be:
DataFrame( [ ["Michigan", "Ann Arbor"], ["Michigan", "Yipsilanti"] ],
columns=["State", "RegionName"] )
Accomplish the following cleaning:
1. For "State", removing characters from "[" to the end.
2. For "RegionName", when applicable, removing every character from " (" to the end.
3. Depending on how you read the data, you may need to remove newline character '\n'. """
towns_by_state = {}
towns = []
with open('data/college_towns.txt') as fin:
for line in fin:
if '[edit]' in line:
if len(towns) > 1:
towns_by_state[state] = towns
state = line.split('[')[0].strip()
towns = []
elif (line.find(',') != -1) and (line.find('(') != -1) and (line.find(',') < line.find('(')) :
town = line.split(',')[0].strip()
towns.append(town)
elif line.find('(') != -1:
town = line.split('(')[0].strip()
towns.append(town)
elif line.find(',') != -1:
town = line.split(',')[0].strip()
towns.append(town)
state_town_tups = [tuple((state, town)) for state, towns in towns_by_state.items() for town in towns]
df = pd.DataFrame(data=state_town_tups, columns=['State', 'RegionName'])
df.State.map(states)
return df
get_list_of_university_towns().head()
| State | RegionName | |
|---|---|---|
| 0 | North Dakota | Fargo |
| 1 | North Dakota | Grand Forks |
| 2 | Colorado | Alamosa |
| 3 | Colorado | Boulder |
| 4 | Colorado | Durango |
def gdp_data():
"""Return a dataframe containing the quarterly GDP data expressed in 2009 dollars."""
df = pd.read_excel('data/gdplev.xls',
skiprows=7,
usecols=[4, 5, 6],
names=['qtr', 'gdp_curr', 'gdp_2009'])
return df
gdp_data().head()
| qtr | gdp_curr | gdp_2009 | |
|---|---|---|---|
| 0 | 1947q1 | 243.1 | 1934.5 |
| 1 | 1947q2 | 246.3 | 1932.3 |
| 2 | 1947q3 | 250.1 | 1930.3 |
| 3 | 1947q4 | 260.3 | 1960.7 |
| 4 | 1948q1 | 266.2 | 1989.5 |
# better approach
def qtr_to_prd(df):
"""Return the provided dataframe converting the quarterly dates expressed as strings
to Pandas' Period objects contained in the 'date' column, year in the 'year' column
and the number of the quarter in the 'qtr' column. """
df['date'] = pd.to_datetime(df.qtr).dt.to_period('q')
df['year'] = df['date'].dt.year
df['qtr'] = df['date'].dt.quarter
return df
qtr_to_prd(gdp_data()).head()
| qtr | gdp_curr | gdp_2009 | date | year | |
|---|---|---|---|---|---|
| 0 | 1 | 243.1 | 1934.5 | 1947Q1 | 1947 |
| 1 | 2 | 246.3 | 1932.3 | 1947Q2 | 1947 |
| 2 | 3 | 250.1 | 1930.3 | 1947Q3 | 1947 |
| 3 | 4 | 260.3 | 1960.7 | 1947Q4 | 1947 |
| 4 | 1 | 266.2 | 1989.5 | 1948Q1 | 1948 |
# an alternate approach using pandas "str" accessor
def qrt_to_dt(df):
"""Return the provided dataframe converting the quarterly dates expressed as strings
to Pandas' Period objects contained in the 'date' column, year in the 'year' column
and the number of the quarter in the 'qtr' column. """
df['date'] = df.qtr.copy()
df[['year', 'qtr']] = df['qtr'].str.split('q', expand=True)
df.year = df.year.astype(int)
return df
def gdp_change(df):
"""Return a Series containing the differences between an element
and the value in the previous row of the gdp_2009 column."""
return df.gdp_2009.diff()
def is_increasing(df):
"""Return a Series of floating point values containing 1.0 if the value
in the 'delta' column is greater than 0, otherwise 0.0 is returned."""
return (df['delta'] > 0).astype(float)
df = gdp_data()
df = qtr_to_prd(df).set_index('date')
df['delta'] = gdp_change(df)
df['increasing'] = is_increasing(df)
df.head()
| qtr | gdp_curr | gdp_2009 | year | delta | increasing | |
|---|---|---|---|---|---|---|
| date | ||||||
| 1947Q1 | 1 | 243.1 | 1934.5 | 1947 | NaN | 0.0 |
| 1947Q2 | 2 | 246.3 | 1932.3 | 1947 | -2.2 | 0.0 |
| 1947Q3 | 3 | 250.1 | 1930.3 | 1947 | -2.0 | 0.0 |
| 1947Q4 | 4 | 260.3 | 1960.7 | 1947 | 30.4 | 1.0 |
| 1948Q1 | 1 | 266.2 | 1989.5 | 1948 | 28.8 | 1.0 |
def recession_prep(df):
"""Return the dataframe with columns added that support analysis of recessions.
In particular, determine if GDP is increasing or decreasing by using the shift method
to create a Series of duplicated values that have been shifted by the number of
rows specified. Together the shifted columns allow for the quarter in which a recession
starts and ends is identified."""
df = qtr_to_prd(df).set_index('date')
df['delta'] = gdp_change(df)
df['increasing'] = is_increasing(df)
df['prv1'] = df['increasing'].shift(1) # look back one
df['prv2'] = df['increasing'].shift(2)
df['curr'] = df['increasing']
df['nxt1'] = df['increasing'].shift(-1) # look ahead one
df['nxt2'] = df['increasing'].shift(-2)
df['start'] = ((df['prv1']==1) & (df['curr']==0) & (df['nxt1']==0)).astype(float)
df['end'] = ((df['prv2']==0) & (df['prv1']==1) & (df['curr']==1)).astype(float)
return df
recession_prep(gdp_data()).loc['2007q3':'2010q4']
| qtr | gdp_curr | gdp_2009 | year | delta | increasing | prv1 | prv2 | curr | nxt1 | nxt2 | start | end | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||
| 2007Q3 | 3 | 14569.7 | 14938.5 | 2007 | 99.8 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 2007Q4 | 4 | 14685.3 | 14991.8 | 2007 | 53.3 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2008Q1 | 1 | 14668.4 | 14889.5 | 2008 | -102.3 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 2008Q2 | 2 | 14813.0 | 14963.4 | 2008 | 73.9 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2008Q3 | 3 | 14843.0 | 14891.6 | 2008 | -71.8 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2008Q4 | 4 | 14549.9 | 14577.0 | 2008 | -314.6 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2009Q1 | 1 | 14383.9 | 14375.0 | 2009 | -202.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2009Q2 | 2 | 14340.4 | 14355.6 | 2009 | -19.4 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 2009Q3 | 3 | 14384.1 | 14402.5 | 2009 | 46.9 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 2009Q4 | 4 | 14566.5 | 14541.9 | 2009 | 139.4 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| 2010Q1 | 1 | 14681.1 | 14604.8 | 2010 | 62.9 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 2010Q2 | 2 | 14888.6 | 14745.9 | 2010 | 141.1 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 2010Q3 | 3 | 15057.7 | 14845.5 | 2010 | 99.6 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 2010Q4 | 4 | 15230.2 | 14939.0 | 2010 | 93.5 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
def get_recessions(df):
"""Return list of tuples containing the starting and ending dates for recessions."""
df = df.loc['2000q1':]
recessions = []
is_recession = False
start, end = None, None
for index, row in df.iterrows():
if row['start'] == 1.0:
start = index
is_recession = True
elif is_recession and row['end'] == 1.0:
end = index
is_recession = False
recessions.append((start.strftime('%Yq%q'), end.strftime('%Yq%q')))
return recessions
get_recessions(recession_prep(gdp_data()))
[('2008q3', '2009q4')]
def get_recession_start():
"""Returns the year and quarter of the recession start time as a
string value in a format such as 2005q3."""
# only one recession during this period, so no need to loop over start, end tuples
start, end = get_recessions(recession_prep(gdp_data()))[0]
return start
get_recession_start()
'2008q3'
def get_recession_end():
"""Returns the year and quarter of the recession end time as a
string value in a format such as 2005q3."""
# only one recession during this period, so no need to loop over start, end tuples
start, end = get_recessions(recession_prep(gdp_data()))[0]
return end
get_recession_end()
'2009q4'
def get_recession_bottom():
"""Returns the year and quarter of the recession bottom time as a
string value in a format such as 2005q3."""
df = recession_prep(gdp_data())
start, end = get_recessions(df)[0]
return df.loc[start:end, 'gdp_2009'].idxmin().strftime('%Yq%q')
get_recession_bottom()
'2009q2'
def convert_housing_data_to_quarters():
"""Converts the housing data to quarters and returns it as mean
values in a dataframe. This dataframe should be a dataframe with
columns for 2000q1 through 2016q3, and should have a multi-index
in the shape of ["State","RegionName"].
"""
df = pd.read_csv('data/zillow_homes_prices_by_city.csv',
dtype={'RegionID': 'str',
'RegionName': 'str',
'State': 'str',
'Metro': 'str',
'CountyName': 'str',
'SizeRank': 'int'})
region_id_df = df[['RegionID', 'RegionName', 'State', 'Metro', 'CountyName', 'SizeRank']]
region_id_df = region_id_df.assign(State=df.State.map(states))
region_id_df.head()
df = df.drop(['RegionName', 'State', 'Metro', 'CountyName', 'SizeRank'], axis=1)
df = pd.melt(df,
id_vars=['RegionID'],
var_name='Date',
value_name='MedianSalesPrice')
df = df.set_index(pd.to_datetime(df.Date)).sort_index()
df = df.drop('Date', axis=1)
df = df.loc['2000-01-01':]
region_mean_df = df.reset_index().groupby([pd.Grouper(freq='Q', key='Date'), 'RegionID']).mean()
joined_df = pd.merge(region_id_df, region_mean_df.reset_index(), how='inner', on='RegionID')
# Note: Pivoting on State and RegionName without RegionID reduces the number of rows to 10592.
# Only by pivoting on all three and later dropping RegionID can I get the correct number of rows (10730)
# Finding this was truly painful.
pivot_df = joined_df.pivot_table(index=['State', 'RegionID', 'RegionName'], columns='Date', values='MedianSalesPrice')
pivot_df.columns = [c.lower() for c in pivot_df.columns.to_period('Q').format()]
pivot_df.index = pivot_df.index.droplevel('RegionID')
return pivot_df
# save dataframe as csv
filepath = './data/effect_of_recession_on_median_home_prices.csv'
convert_housing_data_to_quarters().to_csv(filepath)
def run_ttest():
'''First creates new data showing the decline or growth of housing prices
between the recession start and the recession bottom. Then runs a ttest
comparing the university town values to non-university towns values,
return whether the alternative hypothesis (that the two groups are the same)
is true or not and its p-value.
Return the tuple (different, p, better) where different=True if the t-test is
True at a p<0.01 (we reject the null hypothesis), or different=False, if
otherwise (we cannot reject the null hypothesis). The variable p should
be equal to the exact p-value returned from scipy.stats.ttest_ind(). The
value for better should be either "university town" or "non-university town"
depending on which has a lower mean price ratio (which is equivalent to a
reduced market loss).'''
# group university and non-university towns
univ_towns = get_list_of_university_towns()
univ_towns['Location'] = univ_towns[['State', 'RegionName']].apply(tuple, axis=1)
# get home sales data
sales_df = convert_housing_data_to_quarters().reset_index()
sales_df['Location'] = sales_df[['State', 'RegionName']].apply(tuple, axis=1)
# calculate the ratio of prices from the start to the bottom of the recession
# smaller values indicates that homes retained their value during the recession
sales_df['Price_Ratio'] = sales_df.loc[:, get_recession_start()] / sales_df.loc[:, get_recession_bottom()]
sales_df = sales_df.loc[:, ['Location', 'Price_Ratio']]
sales_df = sales_df.dropna()
# home sales data series for university and other towns
is_univ = sales_df.Location.isin(univ_towns.Location)
univ_sales_df = sales_df.loc[is_univ]
other_sales_df = sales_df.loc[~is_univ]
# compare the means of median home prices
_, p_value = ttest_ind(other_sales_df.Price_Ratio.values, univ_sales_df.Price_Ratio.values)
# interpret the results
if p_value < 0.01:
# reject null hypothesis --> population means are different
different = True
better = 'university town'
else:
# accept null hypothesis --> population means are the same
different = False
better = 'non-university town'
# return results
return different, p_value, better
run_ttest()
(True, 0.0050464756985043489, 'university town')
Results
Median home prices in college towns declined less than other towns during the recession that started in late 2008. In this data set, betting on college towns appears to be a winner though there is a 1 in 100 chance that this conclusion is wrong. Let's dive in a little deeper into the data and see what it shows.
def create_plotting_frame():
# group university and non-university towns
univ_towns = get_list_of_university_towns()
univ_towns['Location'] = univ_towns[['State', 'RegionName']].apply(tuple, axis=1)
# get home sales data
sales_df = convert_housing_data_to_quarters().reset_index()
sales_df['Location'] = sales_df[['State', 'RegionName']].apply(tuple, axis=1)
# calculate a more intuitive price ratio where values above one represent price gains
sales_df['Intuitive_Price_Ratio'] = sales_df.loc[:, get_recession_bottom()] / sales_df.loc[:, get_recession_start()]
sales_df = sales_df.loc[:, ['Location', 'State', 'Intuitive_Price_Ratio']]
sales_df = sales_df.dropna()
# identify and label towns as either college or regular
sales_df = sales_df.assign(Type=sales_df.Location.isin(univ_towns.Location))
sales_df = sales_df.assign(Town=sales_df.Type.map({True:'College', False:'Regular'}))
# replace long state names with two letter abbreviations for plotting
reverse_state_lookup = {long: short for short, long in states.items()}
sales_df = sales_df.assign(State = sales_df.State.apply(reverse_state_lookup.get))
return sales_df
plot_df = create_plotting_frame()
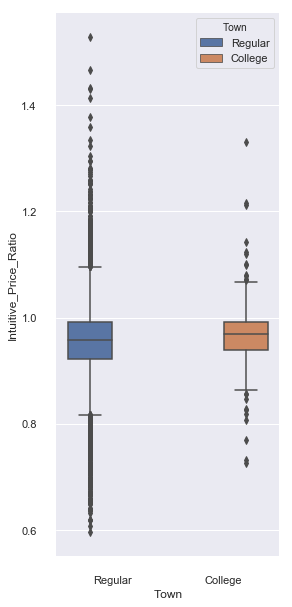
Comparing College and Regular Towns
A price ratio of greater than one indicates that median home prices increased during the recession and values less than one home price decreases. The ratio is formed by dividing the value from the bottom by that of its start. Looking closely at the plot reveals that college towns have a subtly higher median value (indicated by the line in the middle of the box) than other towns. The median value is unaffected by outliers (shown as dots) that comprise less than 1% of all towns. Home prices in college towns were more stable, showing less variance in home prices.
sns.set(rc={'figure.figsize':(4, 10)})
sns.boxplot(x='Town', y='Intuitive_Price_Ratio', hue='Town', data=plot_df)
sns.despine(offset=10, trim=True)
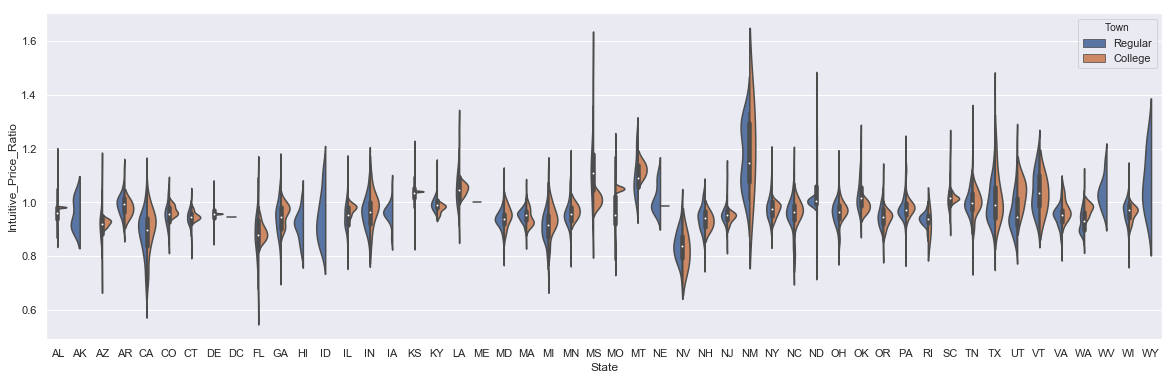
State-Level Median Home Prices
Let's see how values compare by state with New Mexico standing out as one of the housing markets during the recession. The violin plot shows the distribution of home price values by town type for each state.
sns.set(rc={'figure.figsize':(20, 6)})
sns.violinplot(x='State', y='Intuitive_Price_Ratio', hue='Town', data=plot_df, split=True)
<matplotlib.axes._subplots.AxesSubplot at 0x11bc02390>
Best and Worst State Housing Markets
How did home prices change on the state-level? Let's the best and worst states by sorting the price ratio and extract the states with the best and worst-performing home markets.
- Best: New Mexico
- Worst: Nevada
# states with the best housing markets
sorted_states_df = plot_df.groupby(by='State').agg({'Intuitive_Price_Ratio': 'median'}).sort_values(by='Intuitive_Price_Ratio', ascending=False)
sorted_states_df.head(10)
| Intuitive_Price_Ratio | |
|---|---|
| State | |
| NM | 1.147781 |
| MS | 1.108406 |
| MT | 1.090499 |
| WY | 1.055361 |
| LA | 1.047571 |
| KS | 1.036582 |
| VT | 1.036013 |
| WV | 1.027663 |
| OK | 1.015508 |
| SC | 1.015338 |
# states with the worst housing market
sorted_states_df.tail(10)
| Intuitive_Price_Ratio | |
|---|---|
| State | |
| RI | 0.939939 |
| WA | 0.931055 |
| AK | 0.926371 |
| ID | 0.924646 |
| AZ | 0.921471 |
| HI | 0.915682 |
| MI | 0.914556 |
| CA | 0.898245 |
| FL | 0.880623 |
| NV | 0.837595 |
Best and Worst College Towns Housing Markets
Silver City, New Mexico, the home of New Mexico Tech, had a median home price increase of 33% the best in the country. The 27% decline in Riverside, California is the worst of any college town analyzed. Hopefully, they have fully recovered.
# best and worst college towns
sorted_college_df = plot_df[plot_df.Town.str.contains('College')].sort_values(by='Intuitive_Price_Ratio', ascending=False)
top_10 = sorted_college_df.head(10)
top_10
| Location | State | Intuitive_Price_Ratio | Type | Town | |
|---|---|---|---|---|---|
| 5840 | (New Mexico, Silver City) | NM | 1.331176 | True | College |
| 9705 | (Texas, Stephenville) | TX | 1.215334 | True | College |
| 6991 | (North Dakota, Grand Forks) | ND | 1.211294 | True | College |
| 5013 | (Montana, Bozeman) | MT | 1.142552 | True | College |
| 8616 | (Pennsylvania, California) | PA | 1.122962 | True | College |
| 9693 | (Texas, Lubbock) | TX | 1.120328 | True | College |
| 5020 | (Montana, Missoula) | MT | 1.101759 | True | College |
| 2987 | (Indiana, West Lafayette) | IN | 1.099918 | True | College |
| 9819 | (Utah, Salt Lake City) | UT | 1.081056 | True | College |
| 9852 | (Vermont, Burlington) | VT | 1.077434 | True | College |
bottom_10 = sorted_college_df.tail(10)
bottom_10
| Location | State | Intuitive_Price_Ratio | Type | Town | |
|---|---|---|---|---|---|
| 523 | (California, Sacramento) | CA | 0.856530 | True | College |
| 1558 | (Florida, Orlando) | FL | 0.855448 | True | College |
| 2826 | (Indiana, South Bend) | IN | 0.846934 | True | College |
| 4391 | (Michigan, Flint) | MI | 0.828449 | True | College |
| 576 | (California, Merced) | CA | 0.825599 | True | College |
| 963 | (California, Turlock) | CA | 0.818946 | True | College |
| 6802 | (North Carolina, Cullowhee) | NC | 0.806439 | True | College |
| 5045 | (Nevada, Las Vegas) | NV | 0.770192 | True | College |
| 518 | (California, Pomona) | CA | 0.731259 | True | College |
| 862 | (California, Riverside) | CA | 0.726472 | True | College |